静态数据脱敏系统全面升级,为敏感信息穿上“防护衣”
2022-11-2 0:00:00浏览量:2012编辑:管理员来源:天畅
随着5G、大数据、工业互联网、产业互联网、移动互联网、数字经济、数字产业化的推进,数据正变得越来越大,越来越多。“数据安全”成了一个重要的词活跃在行业以及社会大众的面前,各项法律法规的颁布,对企业数据安全的合规提出了更高更严格的标准。

2021年1月8日,有人在某国外论坛中发帖售卖国内某银行1679万笔数据,并放出部分数据样本,数据包括名字、性别、卡号、身份证号、手机号码 、所在城市、联系地址、工作单位、邮编 、工作电话、住宅电话、卡种、发卡行等等。
2021年1月29日,江苏镇江丹阳警方成功侦破一起公安部督办的侵犯公民个人信息案,涉及10多个省市,抓获犯罪嫌疑人30名。由于该案件侵犯对象广,犯罪嫌疑人摒弃传统的网络通讯工具和银行卡转账的收付款方式,采用境外聊天工具和区块链虚拟货币,犯罪手段新颖,社会危害严重,该案被公安部挂牌督办。
2021年6月17日,商丘市睢阳区人民法院 6 月 3 日在裁判文书网公开的刑事判决书显示,两名犯罪分子在淘宝爬取并盗走大量数据。经过检方核实,被盗取的淘宝用户数据 近 12 亿条。淘宝去年 8 月 14 日报警,有黑产人员通过接口,绕过平台风控,批量爬取数据,爬取内容包括买家 UID、淘宝昵称、用户手机号等敏感信息。淘宝在一份声明中表示,没有用户资讯被卖给第三方,也没有发生经济损失。法院裁定,这家公司一名员工收集超过 10 亿条淘宝用户资讯,虽然是用以为客户提供服务,但该员工及其雇主判处三年以上监禁,并处以总计 45 万元人民币的罚款。
作为数据安全防护工作的重要一环,数据脱敏技术和产品已作为常规手段,在开发测试环境构建以及数据外发共享等典型场景中被广泛普及应用。将数据库进行脱敏处理,才能够有效地避免数据库内容泄露。
所谓的数据脱敏,是指在不影响数据分析结果的准确性前提下,对原始数据中的敏感字段进行处理,从而降低数据敏感度和减少个人隐私风险的技术措施。
是指通过对个人信息的技术处理,使得在不借助额外信息的情况下,无法识别个人信息主体。
是指通过对个人信息的技术处理,使得个人信息主体无法被识别或关联,且处理后的信息不能被还原的过程。

如果单纯从“使用效果”来看,数据脱敏所要实现的不过是将用户真实数据迁移至新环境中,并对敏感数据进行变形、遮蔽等处理,达到数据“敏感性降低、标识化消除”的目的。然而,上述貌似简单明确的需求,如果没有专业、复杂的技术支撑,非但无法将安全和便捷带给客户,还会在项目交付实施等环节造成一系列问题和麻烦!透过一系列典型数据脱敏需求,可以看清其背后的产品功能与技术能力差异。
针对目标环境中的敏感数据进行发现,是进行数据脱敏公认的前提。然而,对这项技术的应用除必须考察数据脱敏产品的“发现性能和准确度”外,在实际使用过程中还隐藏着对产品更多“深度能力”的要求,这些能力将决定一款数据脱敏产品能否真正适用于真实复杂的场景。
对于“由多种内容混合在一起“的字段,数据脱敏产品能否准确辨别其中每种数据的类型,同时给出类型占比以供使用者参考抉择?
对于“从数据特征上无法判别敏感属性”的字段,在传统数据脱敏产品的发现逻辑中往往容易被忽略,从而导致敏感数据的泄露。
数据脱敏,看似是描述相关产品“最基础能力”的词语,但在差异化使用场景下却对其有着不同能力的要求;比如客户对脱敏后数据”仿真”质量的要求,就会随着脱敏后数据的实际使用得到验证,从而对数据脱敏产品的“高度仿真”能力提出更多、更高的要求,往往由以下几个难度层级构成:
基础的内容仿真,要求脱敏后数据从“数据类型、长度、格式、内在逻辑和语义”等特性上均与原始数据保持一致,不会对脱敏后数据的使用场景造成无法识别或产生歧义等问题。通常来说,市面上多数脱敏产品通过内置规则,可针对身份证、姓名、银行卡、手机号、地址等常见字段实现上述最基础的仿真要求。但当客户面对五花八门的使用场景时,想要实现脱敏后数据的“高度仿真”,就需要更加灵活的产品技术能力提供支撑。
进阶一步的数据仿真,除对内容进行仿真外,还要求脱敏后的整列数据能够满足某些特征,以避免这些脱敏后数据被分发到分析统计场景后,因为失真降低其实用性。
关联仿真则是更进一步的数据仿真,要求脱敏后数据与其所在行的其他数据能够保留一定的关联关系或运算关系。
脱敏性能,是客户极为关注的产品指标!在一些场景下,客户需要执行“一次全量脱敏后每天增量脱敏”的数据处理逻辑,这就要求脱敏产品必须在规定时间内处理完前一天的增量数据,不然就会直接影响到脱敏目标环境中的数据一致性;而在另一些场景中,对数据脱敏的需求则处于“随用随做”的节奏,且从数据脱敏需求被发出到完成数据脱敏环境的构建,留给相关人员的时间很可能十分紧张。无论面临以上哪种场景,都对大批量数据的脱敏性能提出着新的要求与挑战。
静态数据脱敏系统(简称:SDMS)服务于系统测试、业务培训、数据分发等业务场景,是信创技术产业体系建设和发展不可或缺的一个重要环节。自发布问世以来,产品服务及解决方案已覆盖政务、金融、能源、运营商、教育、医疗等多个行业领域,极大化满足各行业需求,为用户带来了优质的产品服务。目前, SDMS在“自动识别敏感数据——丰富的脱敏算法配置——仿真脱敏保值致用——跨网跨域安全分发”的完整链路能力基础上实现多方位升级,正式推出静态数据脱敏系统全新版本。
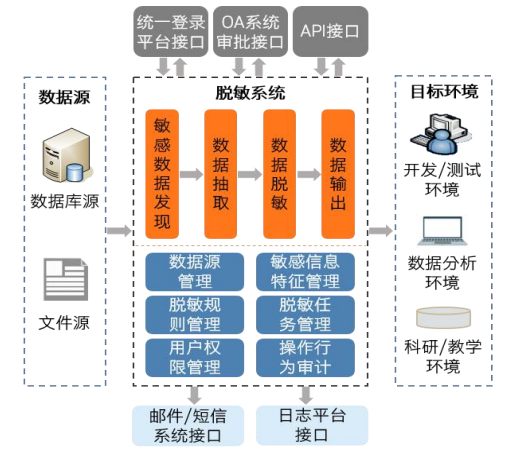
数据库支持类型扩充:
实现了对国产化数据库,包括但不限于:巨衫数据库 SequoiaDB、华为高斯数据库OpenGauss、中兴通讯GoldenDB等数据库的脱敏能力支持。
脱敏算法优化更新:
针对更加繁杂模糊的数据类别、似是而非的数据特征、参差不齐的数据质量等情况,对部分脱敏算法进行了优化更新。在增加敏感数据识别的准确性的同时,提高了脱敏算法混合配置的容易性。
脱敏任务处理能力升级:
通过配置阈值和弹窗提示的方式提高了任务执行的流畅度和异常处理的敏捷度。后续将持续扩展短信提示、邮件提示的能力,实现任务随时随地尽在掌握之中。
系统运维及使用体验提升:
重构了维护平台,包括:服务配置、系统工具、DC工具、JVM 工具、日志分析、版本维护等功能的优化升级。

掌握敏感数据分布:
准确、高效、完整的敏感数据发现为用户安全地执行数据分发、共享工作提供前提和保障。
提高数据脱敏效率:
界面简单易操作,可以自动识别敏感数据,并根据敏感数据的类型使用不同的脱敏算法,同时支持配置定时任务,自动化完成脱敏。
保证数据脱敏有效:
有效保障脱敏后数据的高仿真度和合法性,使其满足原始数据的业务规则,能够代表实际的业务属性,为数据使用者带来真实有效的数据体验。
规范数据共享流程:
有效管理敏感数据申请和外发流程,完整记录数据使用过程,大幅降低数据泄露风险,使安全追溯有据可查。
数据脱敏是大数据时代企业数据化运行治理的必要安全机制,在迎接信创产业新发展机遇的同时,静态数据脱敏系统将不断用对产品的迭代演进、对技术的精益求精、对设计的不断完善,持续创新与发展,凭借灵活的部署方式、高效的脱敏能力、稳定的运行效果赢取更多用户的信赖,在科技革新的时代浪潮中接受愈加严苛的市场检验。